- 1. Overview
- 2. 网络 performance 优化
- 3. 提高 DDR frequency
- 4. RPS wigi
- 5. GRE tunnel multi TX queue
- 6. Tunnel 发送 memcpy
- 7. Netfliter 优化
- 8. DHCP packet capture 对性能的影响
- 9. DPAA 4K errata 对性能的影响
- 10. NXP ODP/ORP 方案
1. Overview
某系统网络转发模型如下:
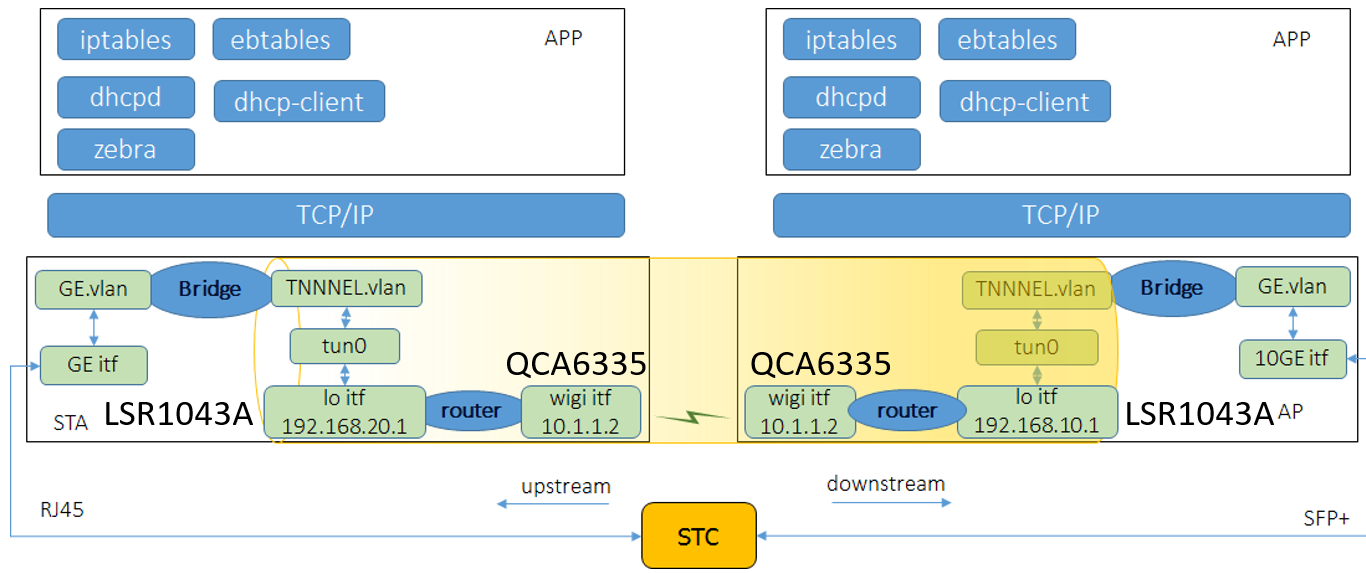
系统配置:
- AP 和 STA 的 CPU 是 NXP ls1043A,4 个 arm A53 core
- AP 和 STA 之间的 wigi interface 线速达 1.6Gbps(MCS8)
- AP 和 STA 采用使用 lo interface 作为 GRE tunnel end point 命令:’ip link add tun0 type gretap local 192.168.10.1 remote 192.168.20.1’ 和ip tun add命令的区别??
- wigi interface 作为 tunnel end point 的网关,这样 tunnel 报文就能在 AP 和 STA 之间传输
STA route命令:
route add -host 192.168.10.1 gw 10.1.1.1 dev wlan0AP route命令:route add -host 192.168.20.1 gw 10.1.1.2 dev wlan0
2. 网络 performance 优化
目标:提高 throughput:大包 throughput 达到线速 1Gbps(当前860Mbps), 小包达到 90Mbps 结果:1024,1518 字节的大包达到线速 1Gbps,64 字节的小包达到 90Mbps.
3. 提高 DDR frequency
Change DDR bus frequency from 300M ->400Mhz(修改 u-boot 硬件配置字),小包性能提升大约 2% 测试工具 lmbench 下载地址: https://sourceforge.net/projects/lmbench/files/latest/download?source=files
4. RPS wigi
高通 wigi 网卡硬件是单队列,使用 RPS 软件多队列技术,单核硬中断收到 packet 之后,软件计算 hash 然后分配到其他 core 去处理,发挥多核优势,提高多流的吞吐量。
About RPS: https://www.kernel.org/doc/Documentation/networking/scaling.txt Receive Packet Steering (RPS) is logically a software implementation of RSS(Receive Side Scaling, multiple receive and transmit descriptor queues). Being in software, it is necessarily called later in the datapath. Whereas RSS selects the queue and hence CPU that will run the hardware interrupt handler, RPS selects the CPU to perform protocol processing above the interrupt handler.
先看通常的 NAPI 收包的流程:
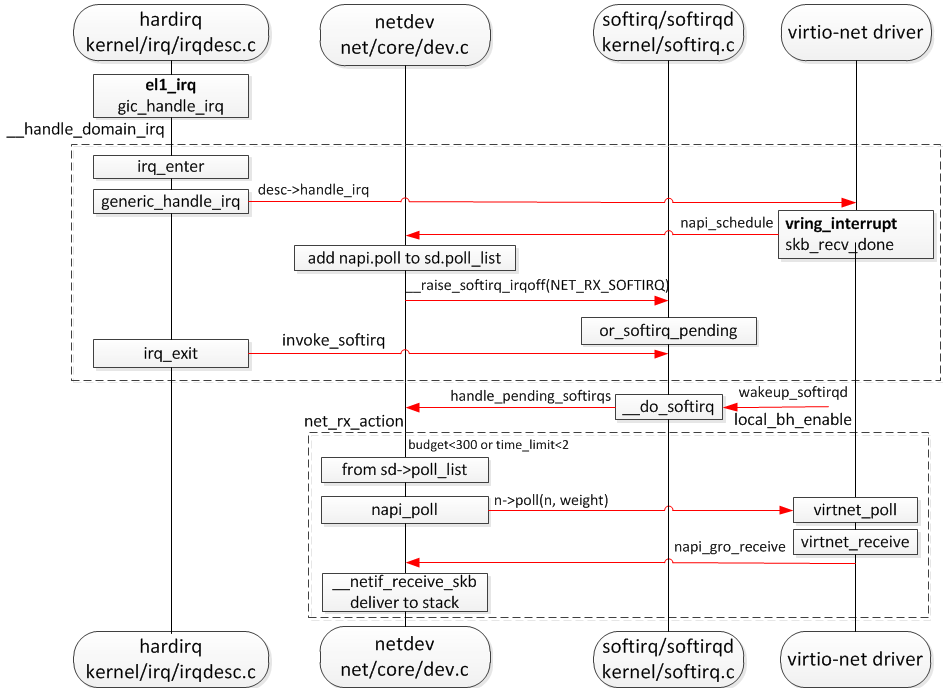
RPS 流程图:
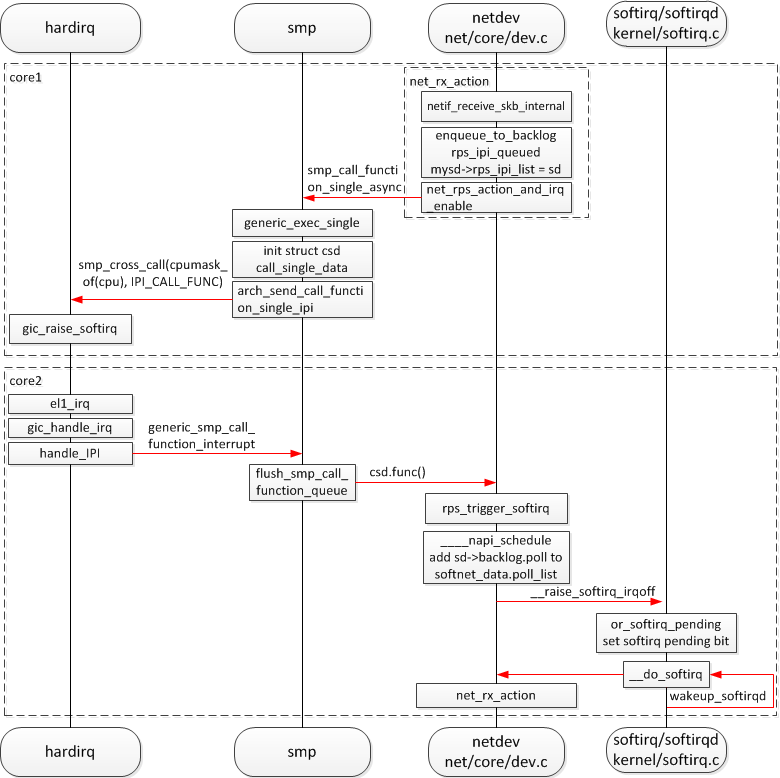
另一个视角看 RPS 流程图:
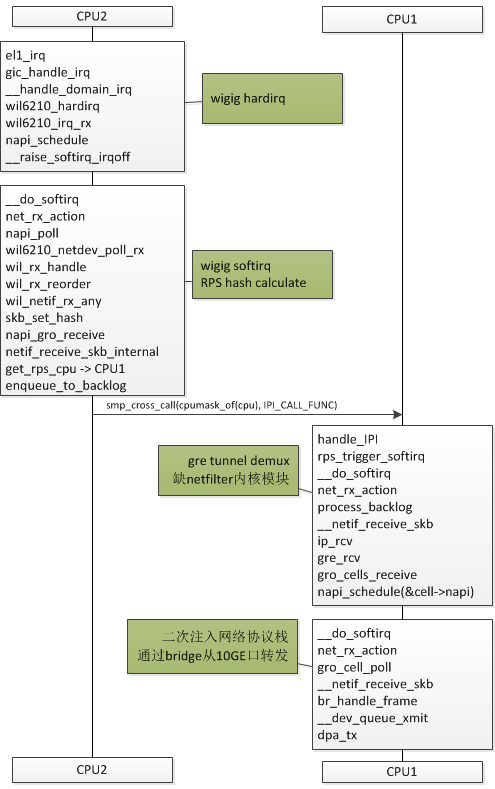
wigi driver 硬件 feature 支持 NETIF_F_RXHASH,rx poll 函数 wil_netif_rx_any 调用 skb_set_hash 设置 skb->l4_hash 为 1,从而在 skb_get_hash 不进行软件 hash 计算;设置 skb->hash 为1,根据用户 RFS 设置进行 core 选择?
if (ndev->features & NETIF_F_RXHASH)
/* fake L4 to ensure it won't be re-calculated later
* set hash to any non-zero value to activate rps
* mechanism, core will be chosen according
* to user-level rps configuration.
*/
skb_set_hash(skb, 1, PKT_HASH_TYPE_L4);
业务模型是转发,不会设置 RFS,所以要打开软件hash进行 hash 计算,为此将 skb_set_hash(skb, 1, PKT_HASH_TYPE_L4) 改为 skb_set_hash(skb, 1, PKT_HASH_TYPE_L3)。 取消 NETIF_F_RXHASH 应该也可以。
5. GRE tunnel multi TX queue
gre tunnel 虚拟设备默认是单队列设备,如下是链路层发送流程图,netdev_pick_tx 选择一个发送队列,如果有多条流发送,就会形成锁竞争造成效率下降,将 tunnel的 发送队列修改为 cpu core 的个数 4 可提高网络吞吐量。
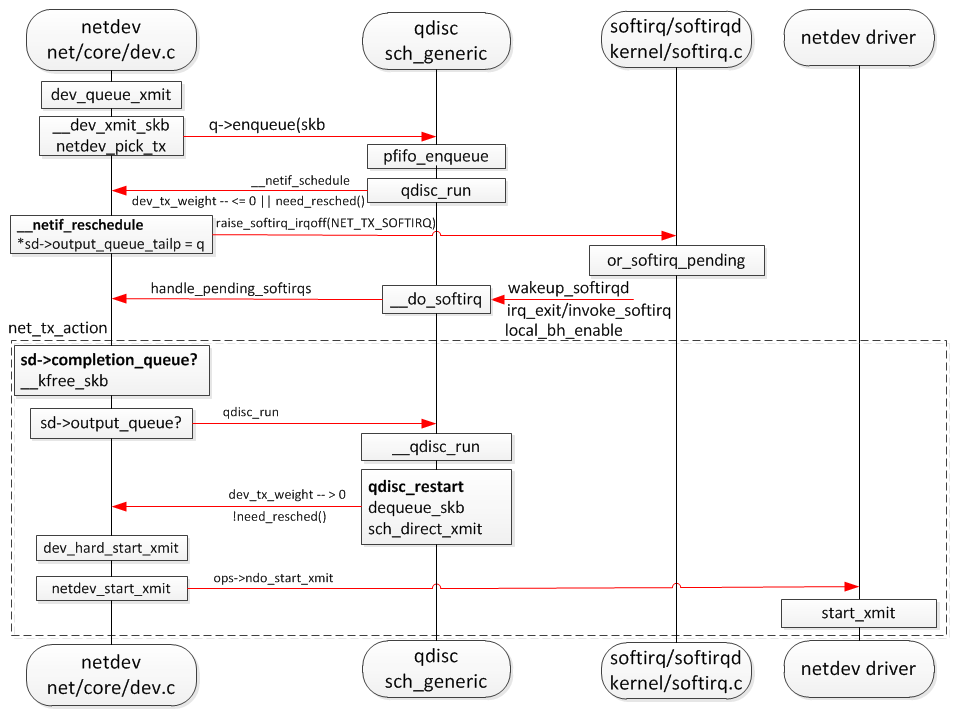
当初直接在源代码里面写死了,后来阅读源代码发现 ip link add 创建虚拟设备的时候可以指定命令行参数来设置收发队列,查看 ip link 的帮助得到验证:
root@hou-1:~# ip link help
Usage: ip link add [link DEV] [ name ] NAME
[ txqueuelen PACKETS ]
[ address LLADDR ]
[ broadcast LLADDR ]
[ mtu MTU ] [index IDX ]
[ numtxqueues QUEUE_COUNT ]
[ numrxqueues QUEUE_COUNT ]
type TYPE [ ARGS ]
... ...
TYPE := { vlan | veth | vcan | dummy | ifb | macvlan | macvtap |
bridge | bond | ipoib | ip6tnl | ipip | sit | vxlan |
gre | gretap | ip6gre | ip6gretap | vti | nlmon |
bond_slave | ipvlan }
6. Tunnel 发送 memcpy
分析火焰图发现 tunnel 发送的时候有大量 memcpy
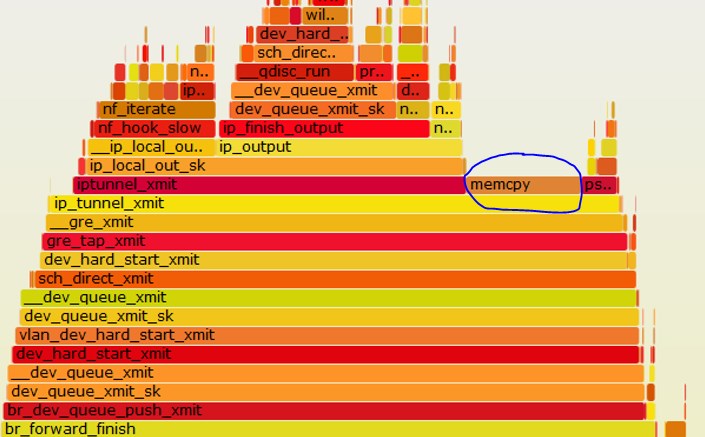
先建立路由或者建 tunnel 命令加 -dev wlan0 参数即 ip link add tun0 type gretap local 192.168.10.1 remote 192.168.20.1 dev wlan0 可以避免 memcpy。
(1) 创建 gre tap tunnel device 的时候,调用 ip_tunnel_bind_dev 计算 dev->needed_headroom
(2) tunnnel xmit 的时候判断当前 skb_headroom(skb) 小于 dev->needed_headroom,就会调用 pskb_expand_head 进行 memcpy
(3) 先建路由再创建 gre tap tunnel device 会使计算出的 dev->needed_headroom 小于 skb_headroom(skb),所以没有 memcpy;反之则有 memcpy。
7. Netfliter 优化
以 downstream 为例,AP 上面的 netfilter hook:

以 downstream 为例,STA 上面的 netfilter hook:
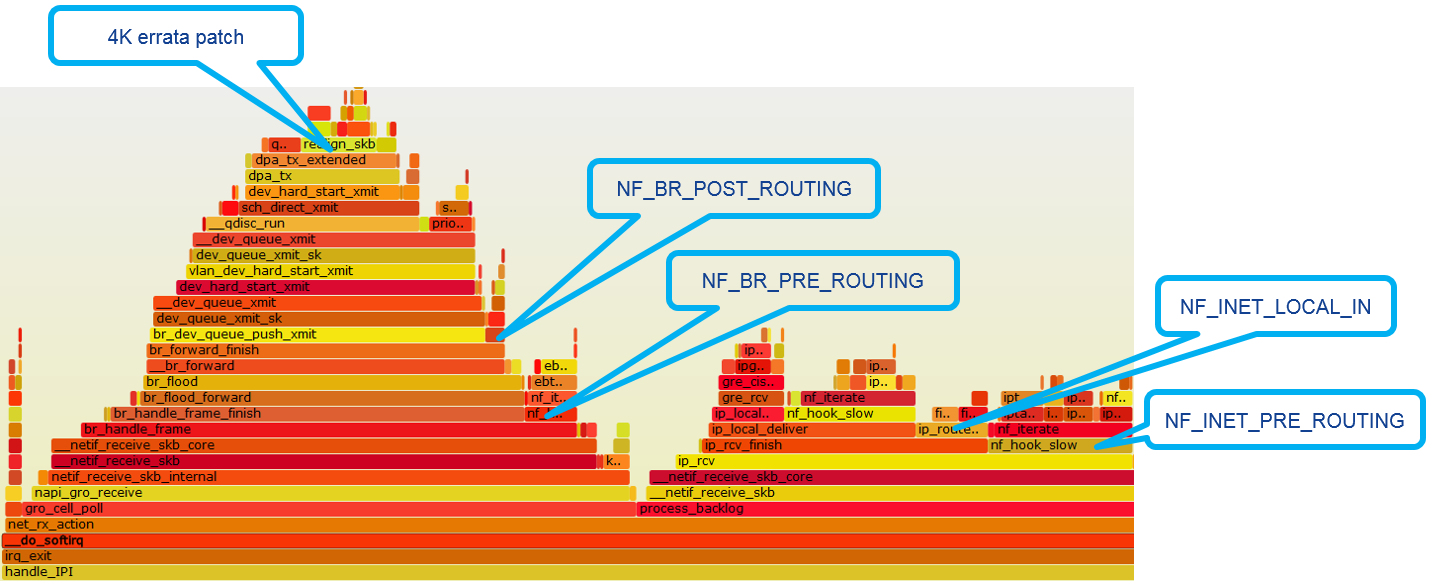
(1) 将 netfilter 部分编译成模块,由应用程序按需加载
(2) 去掉没有用到的 netfilter hook
8. DHCP packet capture 对性能的影响
DHCP 服务器和客户端要收发路径上面抓包,这是造成性能下降的一个因素,无法优化。
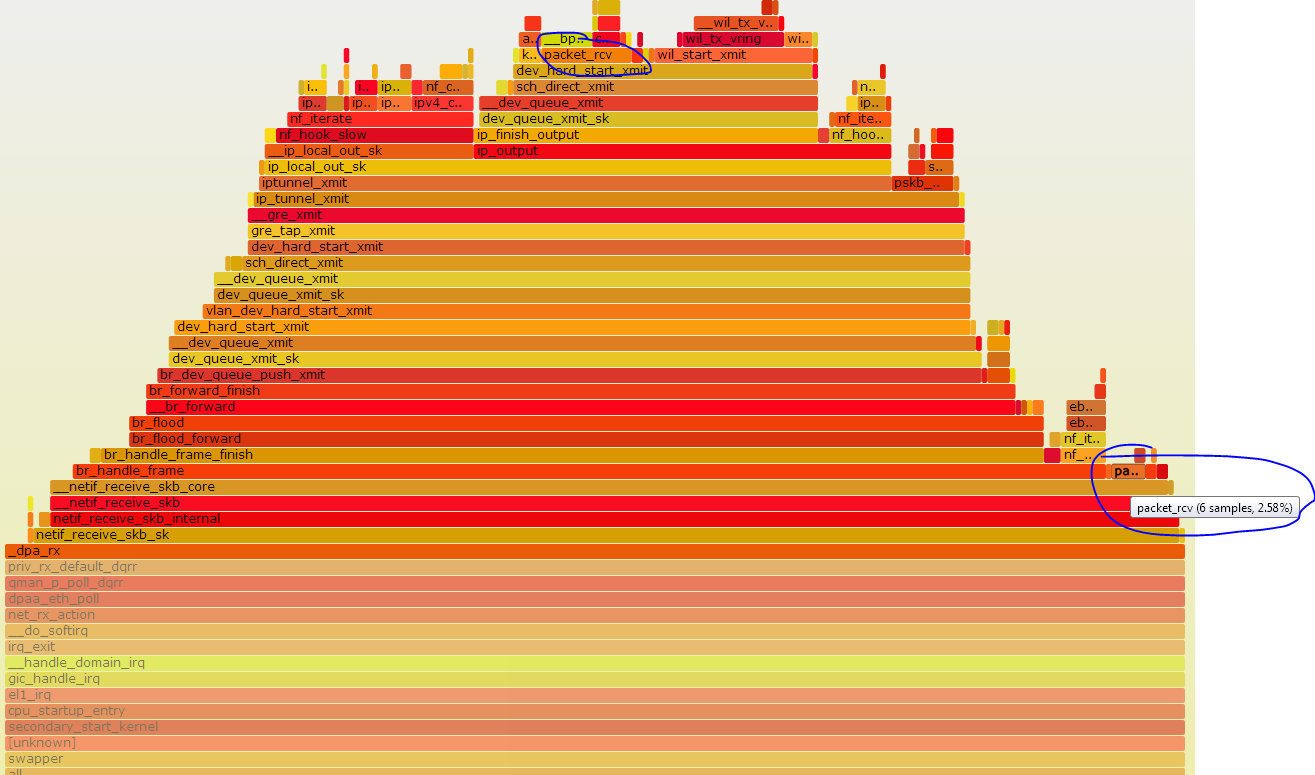
9. DPAA 4K errata 对性能的影响
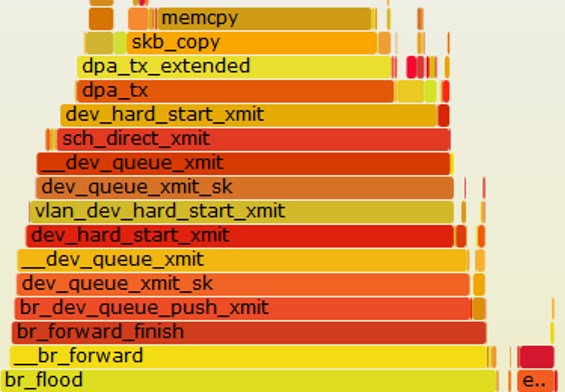
DPAA 硬件设计的缺陷,当 skb 数据缓冲区没有按 4k 边界对齐,dapp 传输的时候会 crash,为此,dapp 驱动在发送的时候判断如果当前 skb 数据缓冲区没有 4k 对齐,将分配一个 4k 对齐的 skb 数据缓冲区,然后将数据拷贝到改 skb,这样就有 memcpy 拷贝。
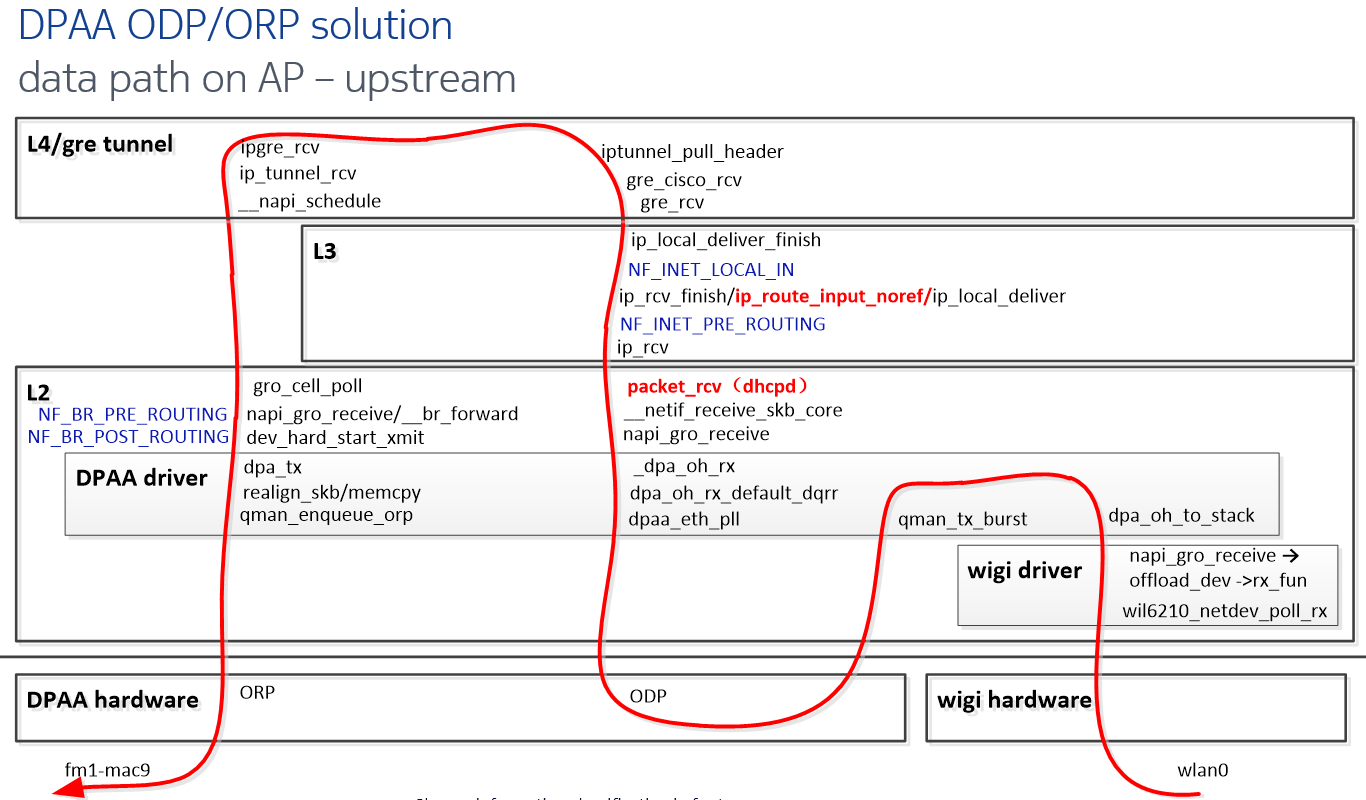
10. NXP ODP/ORP 方案
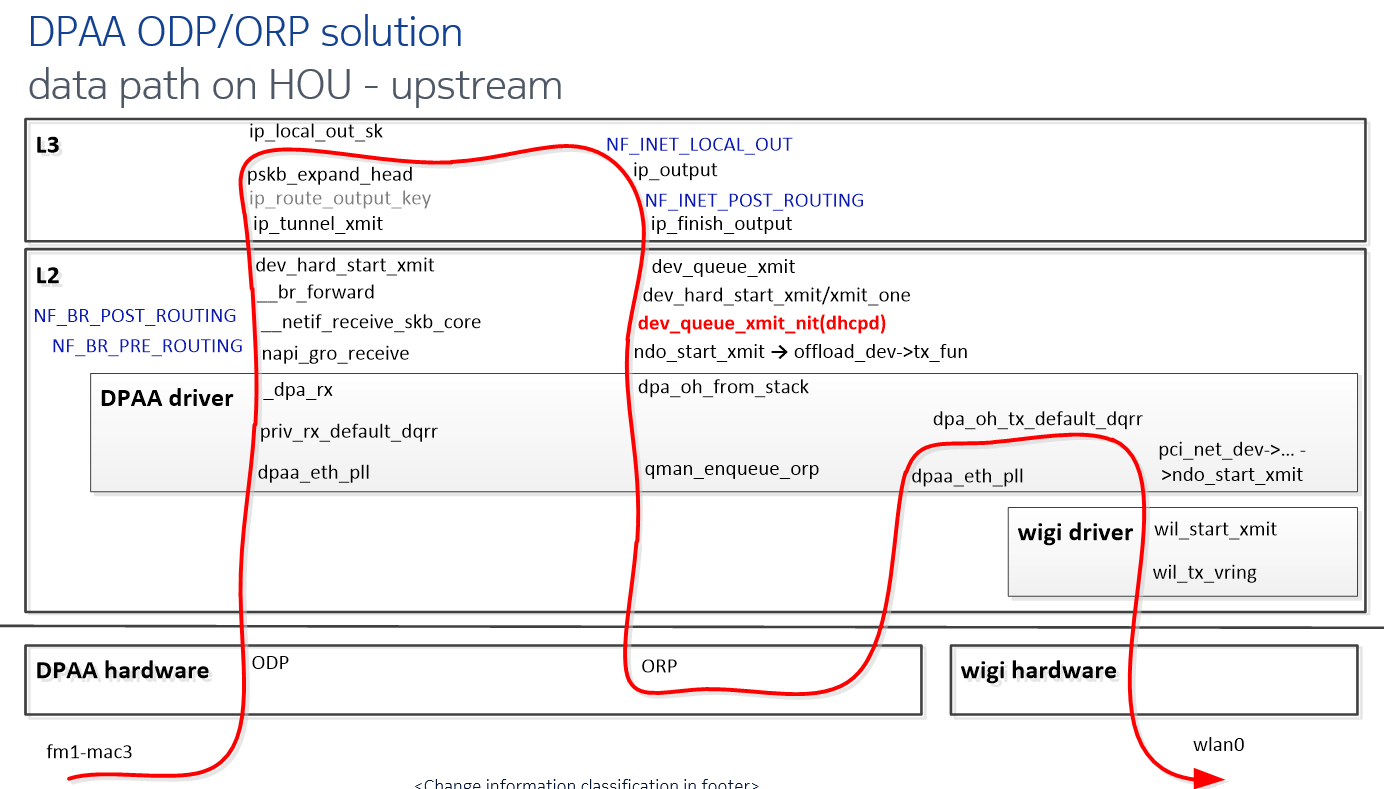
(1) The DPAA QMan provides a mechanism to strictly keep ordering by ODP(Order Definition Point) on ingress and ORP(Order Restoration Point) on egress
(2) By calling API from DPAA offline port driver, single traffic can distribute to multi cores and keep order at the same time.
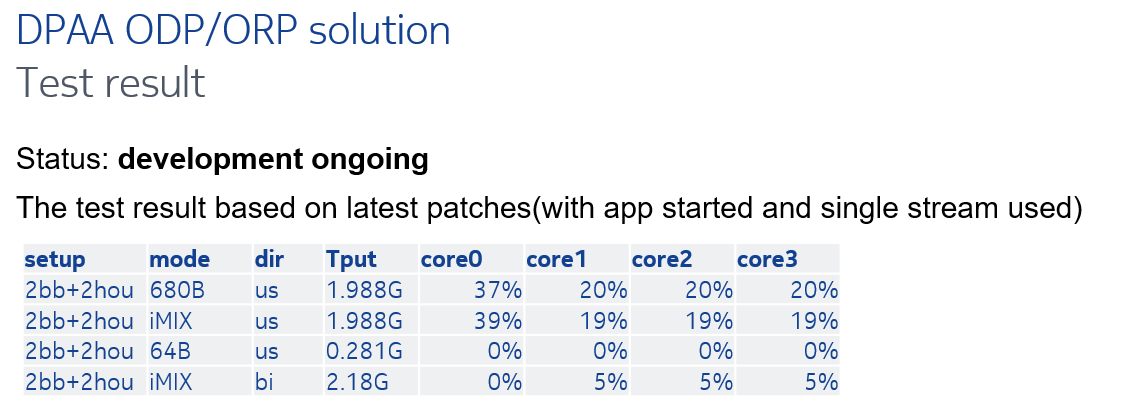
(3) 修改 wigi 驱动,wigi 驱动收包之后调用 dapp 驱动的 api 将数据包发送到 qman 硬件去排序,分发到多核进行处理;wigi 发送之前先将数据包送入 qman 硬件恢复排序,然后调用 wigi 驱动的发送函数。
(4) 这个方案有一个缺点,使能 qos 之后,排队丢包会造成序号丢失,这样 qman 硬件处理会有问题,所以发送的时候 bypass 了 enqueque,造成不能使用 qos。最后被否决了。

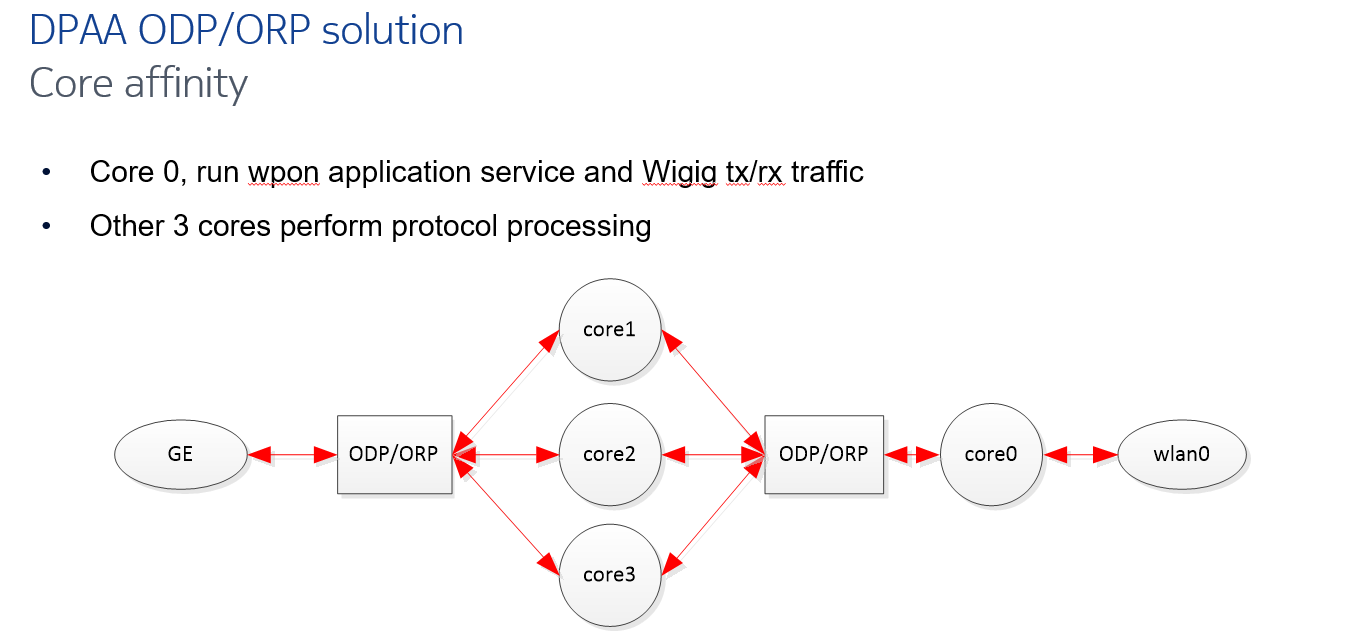
10.1 ODP/ORP core affinity
10.2 ODP/ORP upstream flow
10.3 ODP/ORP downstream flow
10.3 ODP/ORP test result